
Python 爬虫入门
步骤
-
获取网页内容
-
解析网页内容
-
储存或分析数据
HTTP请求和响应
-
GET 方法——获得数据
-
POST方法——创建数据
常见状态码
-
200 OK
-
301 Moved Permanently
-
400 Bad Request
-
401 Unauthoried
-
403 Forbidden
-
404 Not Found
-
500 internal Server Error
-
503 Server Unavailable
Request发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
} # 定义请求头,伪装成浏览器请求
response = requests.get("https://jia.cx/",headers=headers)
print(response) # response 示例
print(response.status_code) # 响应的状态码
if response.ok:
print("请求成功")
print(response.text) # 返回内容
else:
print("请求失败")
Beautiful Soup解析HTML
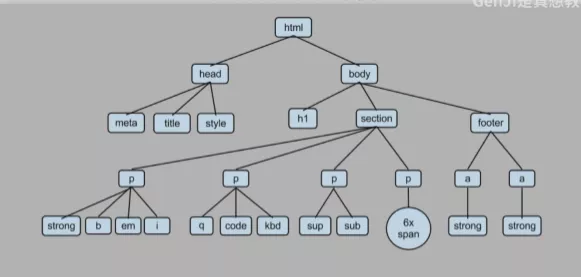
from bs4 import BeautifulSoup
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
url = "https://jia.cx/"
content = requests.get(url, headers=headers)
soup = BeautifulSoup(content.text, 'html.parser')
all_titles = soup.find_all('h1')
print(all_titles)
项目实战
爬取豆瓣TOP 250电影标题
from bs4 import BeautifulSoup
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
for start_num in range(0,250, 25):
url = f"https://movie.douban.com/top250?start={start_num}&filter="
response = requests.get(url, headers=headers)
html = response.text
context = BeautifulSoup(html, 'html.parser')
all_titles = context.findAll("span", attrs={"class": "title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)